|
新闻动态
|
工作进展
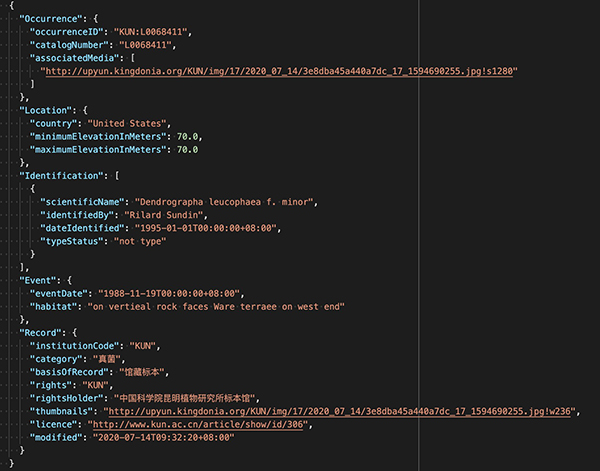
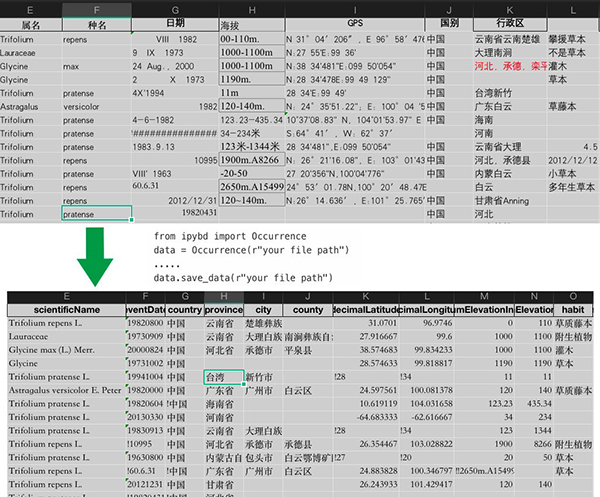
记录某个物种,在什么时间,出现在哪里,处于什么状态,是一件多样性极高的工作。比如要用什么语言、什么术语、什么结构、什么格式、什么媒介去表达和记录。往往不同的平台和个体都可能千差万别。而且这种差异,即便对于经过严格训练的科研工作者,也同样是很难弥合和统一的。学科的“先天”因素决定了生物多样性研究中的很多基础数据必须依赖于人工收集,因此即便制定了相应的标准,也很难彻底的贯彻。这一客观事实,很大程度上影响着全球生物多样性数据平台的发展。事实上相比分子序列等生物信息学数据,生物多样性数据的整合过程走得尤为艰辛。时至今日,我们已经可以很明确的感受到对于标准的应用和理解,可以直接决定一个平台的发展速度和发展高度,而具体到数据管理机构和普通科研人员,数据的一致和规范也会大幅降低数据治理的成本。 因此,构建灵活通用、简单易用的生物多样性数据清洗体系实为当前国内生物多样性信息学发展中较为迫切的工作之一。2020年,NSII特设立“跨类群生物标本数据自清理与自规整程序”专题。该专题成果 ipybd 就是专门针对中文生物多样性数据清洗、统计与分析的开源框架。目前 ipybd 主要致力于构建众源数据集与生物多样性数据库之间的通道。它实现了一个通用的生物多样性数据提取、转换、装载框架,能够显著提升数据平台、数据管理机构、数据使用者对不同来源、不同格式、不同品质、不同规范的数据集进行统一的清洗转换与整合利用的能力,因此可以大幅降低数据处理的门槛和成本,提高数据处理的品质和效率。 ipybd 现有版本已经具备了以下一些能力: 一、 数据的提取与装载 ipybd 选择 pandas.DataFrame作为框架的基础数据结构,这使其在应对不同格式的数据集时,能够借助 pandas 完善的功能接口,实现一致且稳定的数据提取。目前ipybd 支持 Excel, CSV, TEXT, JSON 等文件的数据提取。同时还可直接接收 DataFrame对象或者通过 SQL 语句进一步从各类关系型数据库中提取所需的数据。 二、数据处理方法ipybd 为生物多样性数据的处理专门定制了一些基本的内置数据处理方法,目前这些方法涉及: 物种学名:能够将各类手工转录的拉丁名转换为规范的格式,并可以在线实时的批量获取 POWO, IPNI, 中国生物物种名录上相应物种的最新分类阶元、分类处理、物种图片、发表文献、相关异名等信息; 日期与时间:可以对各类样式,各种手工转录的日期和时间,进行严格的校验、清洗和转换,并可根据需要输出不同样式; 经纬度:可以对各类样式,各种手工转录的经纬度,进行严格的清洗、校验和转换; 中文行政区划:可以对各种自然语言表达的中文县级及其以上的行政区划进行高品质的匹配、校正和转换; 选值:能够为各种字段定义标准的选值和别名转换关系,并根据转换关系,自动完成现有值的规范化; 数值和数值区间:可以对各类数值或数值区间,进行自动化的清洗、校正和转换; 重复值校验:可根据单个属性或多个属性联合标注数据集中的重复值; 空值和空列填充:可以使用自定义值对空值或空列进行必要的填充; 拆分与合并:ipybd 不仅可以对数据列进行各种合并和拆分(比如中英文切分),还可以将单列、多列或整个数据集映射为各种复杂嵌套结构的 Python dict list 对象或者 JSON Object 和 Array,从而为各类数据分析和互联网平台的数据交换工作提供灵活强大的格式转换支持。
行列表格数据可以被 ipybd 转换为具备复杂嵌套结构的 JSON 对象 三、数据模型数据模型是 ipybd 实现数据集自动清洗的核心,ipybd 内置了涵盖物种发现、标签打印、数据交换在内的一系列数据模型,同时还特别针对国内现有的一些生物多样性平台比如 NSII、CVH、Kingdonia 定制了一些专有的数据模型。用户只需通过一两行代码,即可调用这些模型实现众源数据到特定标准数据集的清洗和转换。
三行代码借助 ipybd.Occurrence 模型自动清洗数据的效果 四、自定义数据模型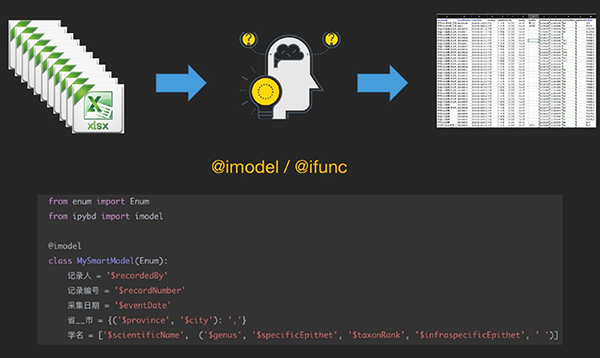 通过 ipybd 自定义一个可以将绝大多数行列表格转换为含有记录人、记录编号、采集日期、省、市、学名六个固定字段的泛化转换模型 ipybd 数据模型同样支持用户自定义。通过 ipbyd 模型定义语义,用户可以快速定制出个性化的数据结构转换模型以及数据结构映射模型。前者可以针对特定数据集构建完全定制化的数据清洗模型,后者则可以根据字段别名的映射关系实现具有良好泛化能力的众源数据清洗模型。此外ipybd 数据模型同样支持数据清洗功能的个性化扩展,用户不仅可以自定义模型结构,还可以自定义数据处理方法。 五、标签打印标签打印是ipybd为标本馆等机构专门定制的功能(当前版本仅支持植物/菌物标签的打印),标签是数字标本信息最初的转录依据。通常中大型标本馆需要接收来自各方的标本,不同来源的标本数据格式千差万别。打印标本标签时,往往需要耗费大量的精力和时间用于检查数据和转换格式。这不仅显著增加了工作量,也增加了人工处理数据出错的风险。
ipybd 可以利用标本采集数据表直接生成附有条形码的采集标签,条形码会根据每份采集的标本份数自动编排。同时,ipybd 还会同步生成一份标本数据表,以避免后期数字化工作中人工处理数据造成的条形码匹配错误。 六、数据统计分析的能力ipybd 原生支持 Pandas 完备的数据统计和分析功能。作为 Python 数据分析生态中的核心库,pandas丰富的应用生态体系也为后续 ipybd 拓展生物多样性相关的分析能力提供了坚实的开发基础。 七、拥抱开源ipybd 是开源的,遵从 GNU General Public License v3.0 许可。 详细的使用说明和开源项目请见 GitHub: https://github.com/leisux/ipybd 欢迎有兴趣的同行 Fork ipybd。 (责任编辑:李雪)
|

版权所有 Copyright © 2002-2025 中国科学院昆明植物研究所,All Rights Reserved 【滇ICP备05000394号】
地址:中国云南省昆明市蓝黑路132号 邮政编码:650201
点击这里联系我们